

其字符串为
复制代码 代码如下:
Array
(
[tt] => Array
(
[table] => qqttcode
[hitcode] => 1
)
[ww] => Array
(
[table] => qqwwcode
[hitcode] =>
)
[pp] => Array
(
[table] => qqppcode
[hitcode] => Array
(
[table] => qqppcode
[hitcode] =>
)
)
)
CFC4N给出一下结果:
复制代码 代码如下:
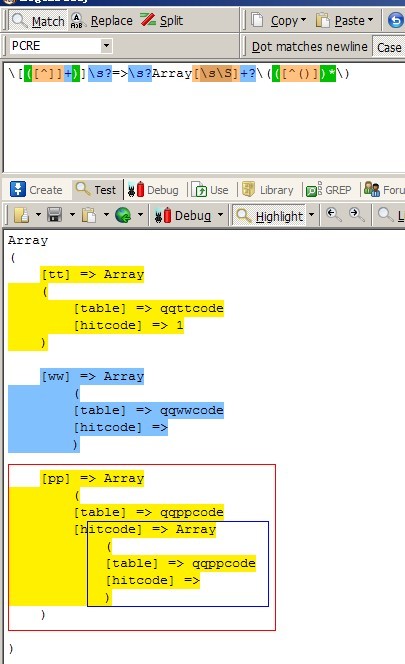
$strRge1 = '/([([^]]+)]s?=>s?)?Array[sS]+?(([^()]|(?R))*)/i';
$arrReturn = array();
if (preg_match_all($strRge1,$str,$tt1))
{
$arrReturn = getarray($tt1[0][0]);
}
$arrReturn2 = array();
foreach ($arrReturn as $k => $v)
{
$arrReturn2[$k] = $v[$k];
}
print_r($arrReturn2);
function getarray ($strContents)
{
$arrTemp = array();
$strRge = '/[([^]]+)]s?=>s?Array[sS]+?(([^()]|(?R))*)/i';
$strReg2 = '/[([^]]+?)]s?=>s?([dw]+)?/';
if (preg_match_all($strRge,$strContents,$strTemp))
{
$num = count($strTemp[1]);
if ($num > '1')
{
for ($i=0; $i<$num; $i++)
{
if (preg_match_all($strRge,$strTemp[0][$i],$arrTTT))
{
$arrTemp[$strTemp[1][$i]] = array();
$arrTemp[$strTemp[1][$i]] = getarray($strTemp[0][$i]);
}
else
{
$arrTemp[$strTemp[1][$i]] = $strTemp[0][$i];
}
}
}
else
{
$arrTemp[$strTemp[1][0]] = array();
$arrTemp2 = array();
if (preg_match_all($strReg2, $strTemp[0][0],$straa))
{
$num = count($straa[0]);
for ($i=0; $i<$num-1; $i++)
{
$arrTemp2[$straa[1][$i+1]] = $straa[2][$i+1];
}
}
$arrTemp[$strTemp[1][0]] = $arrTemp2;
}
}
return $arrTemp;
}
结果是可以用的。但是发现其只能用于固定的三层嵌套,假如N层的话,无法用这个函数了,后来,我又改造一下那个正则,改为
复制代码 代码如下:
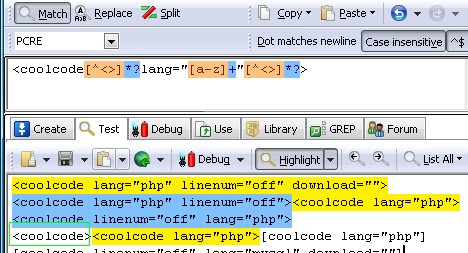
$strRge1 = '/[(([^]]+)]s?=>s?Array[s]+?(([^()])+|(?R)))+/i';
但是,并不能解决问题。。各位看官,您认为,我的误区在哪里呢?
附 第一个正则截图
更改后正则匹配截图
朋友乙:要求批量给html字符串中a标签中不包含title属性的标签添加title,而且,其title内容为到之间的文本。。
CFC4N给出答案为:
复制代码 代码如下:
$str = 'ssssssssssssssssssssssssssss';
$str = preg_replace('%
print_r($str);
复制代码 代码如下:
$str = 'ssssssssssssssssssssssssssss';
$str = preg_replace('%
print_r($str);
各位看官,您认为,CFC4N写的正则表达式里,哪些还可以优化呢?这个效率是不是不高??
朋友丙:要求过滤非本域名,或者非本子域名的其他域名的UBB标签链接,一旦包含,直接替换成其中间的文本,比如例子字符串如下
复制代码 代码如下:
[url=http://www.sadas.cn]baidu[/url]
[url=www.ggasdwe.com]百度[/url]
[url=http://www.qq.com/index.php]QQ[/url]
[url=http://www.miyifun.com/index.html]其他
[/url]
[url=pc.qq.com/index.php]PC QQ[/url]
其中,字符串中不确定有几个换行等其他字符,而且,不确定url的UBB标签中的网址中是否包含http://,不确定二级域名或者三级域名
CFC4N给出的正则以及PHP代码如下
复制代码 代码如下:
$str = '[url=http://www.sadas.cn]baidu[/url]
[url=www.ggasdwe.com]百度[/url]
[url=http://www.qq.com/index.php]QQ[/url]
[url=http://www.miyifun.com/index.html]其他
[/url]
[url=pc.qq.com/index.php]PC QQ[/url]';
print_r(preg_replace('%[url=(http://)?(?:(?!qq.com)[^]])*][r|rn]*([sS]+?)[r|rn]*[/url]%i','2',$str));
各位看官,您认为这里哪里是多余的?还可以进行哪些正则的优化来提高效率?如果没看懂,那您的疑问在哪里?
朋友丁:要求读取squid的配置文件中,起作用的行,也就是没有#开头进行注释的行。
其中,squid的配置文件内字符串见附件中
squid的配置文件内容
CFC4N给出正则代码如下
复制代码 代码如下:
preg_match_all('/^(?!#).+?$/m', file_get_contents('squid.conf'), $regs);
print_r($regs[0]);
运行截图 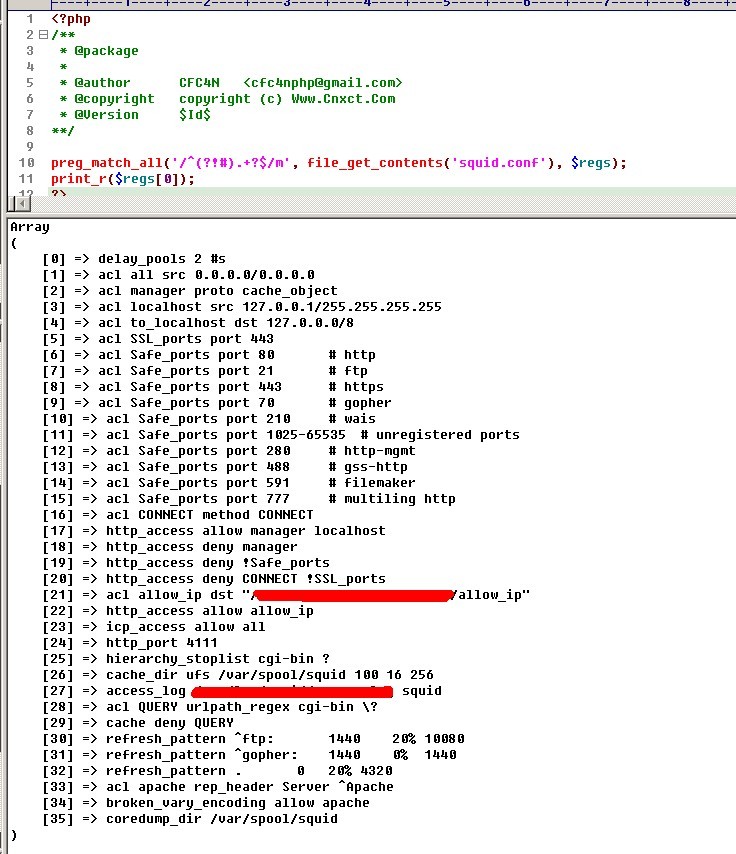
看官们,您认为,这个正则还有哪些没注意到的点?能否正确无误的匹配到朋友丁所需要的内容?您有疑问吗?
PS:以上正则,均为PCRE引擎。。其中,PHP代码的正则递归(迭代)部分,仅限于支持递归正则的引擎代码适用。。
感谢rex老大指点关于(?!)零宽断言非匹配的特性后接匹配规则可能无效的问题。



