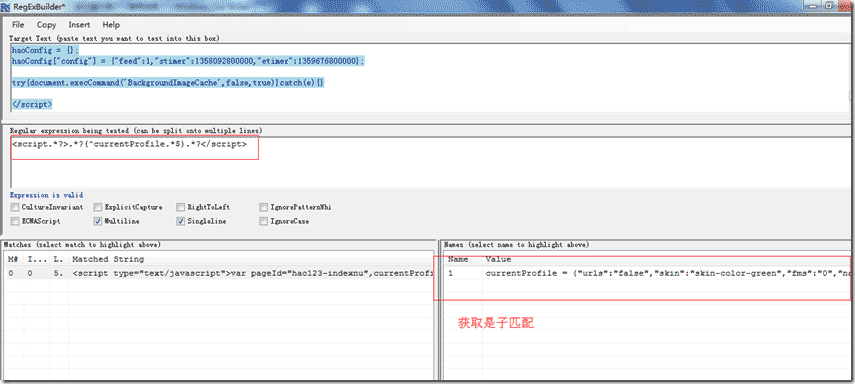
继上几篇正则表达式相关说明(详情:正则表达式 ),我们今天继续讨论下,它的单行,多行模式使用,及容易出现错误地方。单行,多行模式,都是正则表达式的模式修饰符里面出现的参数。目前常用正则表达式都有该使用选项,如:javascript 正则表达式,一般是:”/正则表达式匹配字符/修饰符“ ,最后一个”/” 后面是修饰符。然后,php也是类似的,c#,python等,一般调用正则表达式的匹配函数,都有一个另外选项的,设置模式。
单行、多行模式容易出现理解错误
为什么说,容易出现理解错误呢,它们英文对应说明是:SingleLine ,MultiLine,刚好是单行、多行意思。因此,很多朋友就会从字面理解里面,得出以下结论:(哈哈、刚刚使用,我也是这些朋友中一员)
1、单行,就是从头到尾匹配,多行就是如果匹配字符串,里面有换行符,就匹配到之前
2、单行跟多行是冲突的,一次只能指定一个选项,不能同时使用
这样来理解其实,很容易就会这样的。我们来看看,官方手册里面怎么说的。
单行、多行模式官方解释
模式符
描述
s(单行)
如果设置了这个修饰符, 模式中的点号元字符匹配所有字符, 包含换行符. 如果没有这个 修饰符, 点号不匹配换行符
m(多行)
目标字符串是由单行字符组成的(然而实际上它可能会包含多行), “行首”元字符(^)仅匹配字符串的开始位置, 而”行末”元字符($)仅匹配字符串末尾。当这个修饰符设置之后, “行首”和”行末”就会匹配目标字符串中任意换行符(n)之前或之后
通过上面说明,其实这2个修饰符都只是,修改正则表达式常见元字符的匹配范围了。如果加”s”修饰符,元字符”.” 将能够匹配换行符(n),如果加”m”修饰符,元字符”$”,将只匹配到”n”字符前;元字符”^”,将匹配到”n”字符后。我们还是举例说明吧!(下面关于正则表达式?字符,可以看看前面一节:正则表达式(regex) 贪婪模式、懒惰模式使用)
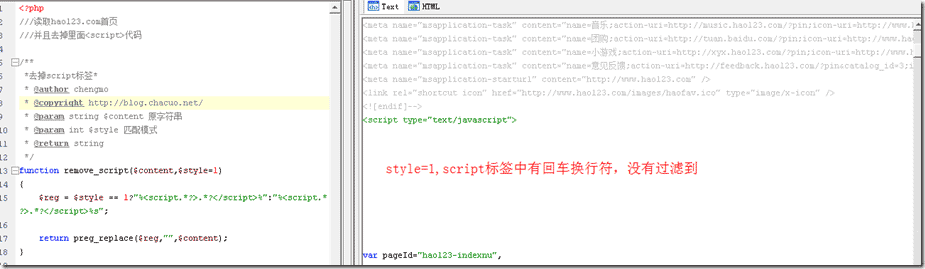
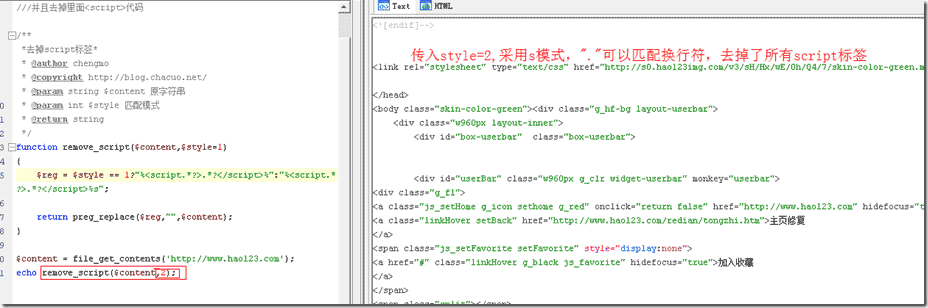
举例,看单行应用
<?php
///读取hao123.com首页
///并且去掉里面script代码
/**
*去掉script标签*
* @author chengmo
* @copyright http://blog.chacuo.net/
* @param string $content 原字符串
* @param int $style 匹配模式
* @return string
*/
function remove_script($content,$style=1)
{
$reg = $style == 1?"%.*?%":"%.*?%s";
return preg_replace($reg,"",$content);
}
$content = file_get_contents('http://www.hao123.com');
echo remove_script($content);
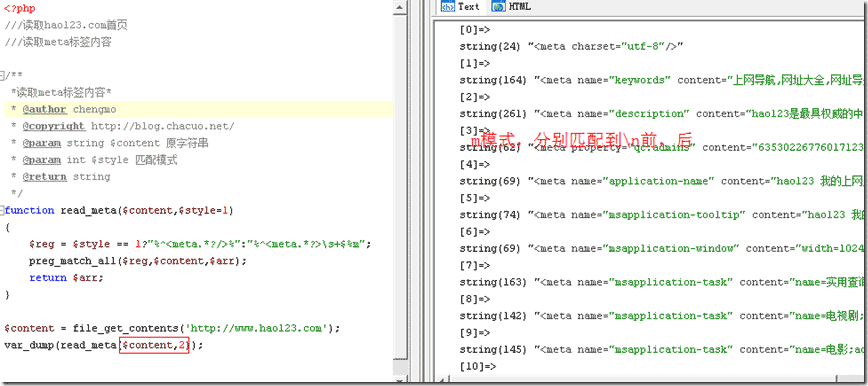
举例,看多行应用
<?php
///读取hao123.com首页
///读取meta标签内容
/**
*读取meta标签内容*
* @author chengmo
* @copyright http://blog.chacuo.net/
* @param string $content 原字符串
* @param int $style 匹配模式
* @return string
*/
function read_meta($content,$style=1)
{
$reg = $style == 1?"%^s+$%m";
preg_match_all($reg,$content,$arr);
return $arr;
}
$content = file_get_contents('http://www.hao123.com');
var_dump(read_meta($content));

后记:s,m 修饰符只对,几个特殊元字符有改变。如果你正则表达式中没有那几个元字符。开启s,m字符前后将没有什么变化的。对于上面读取hao123.com代码,我们可以继续同时使用s,m模式。如:”%