这里说的正则表达式优化,主要是针对目前常用的NFA模式正则表达式,详细可以参考:正则表达式匹配解析过程探讨分析(正则表达式匹配原理)。从上面例子,我们可以推断出,影响NFA类正则表达式(常见语言:GNU Emacs,Java,ergp,less,more,.NET语言,
PCRE library,Perl,PHP,Python,Ruby,sed,vi )其实主要是它的“回溯”,减少“回溯”次数(减少循环查找同一个字符次数),是提高性能的主要方法。 我们来看个例子:
源字符串:
匹配要求,匹配
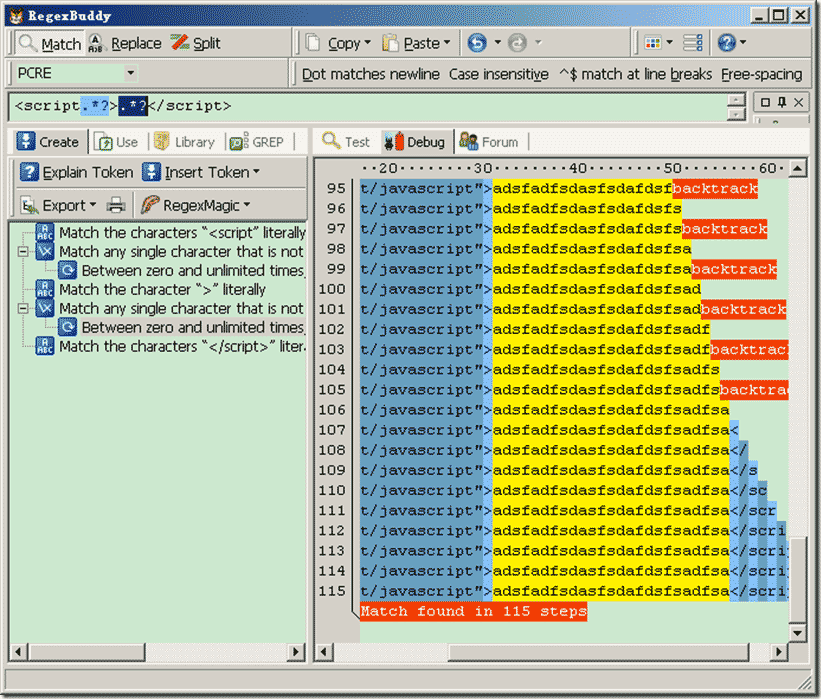
常见写法(1),因为 正则表达式: 总共花费115步,回溯了:48次。 因为我们使用”.”字符,匹配默认情况下除了n之外所有字符。
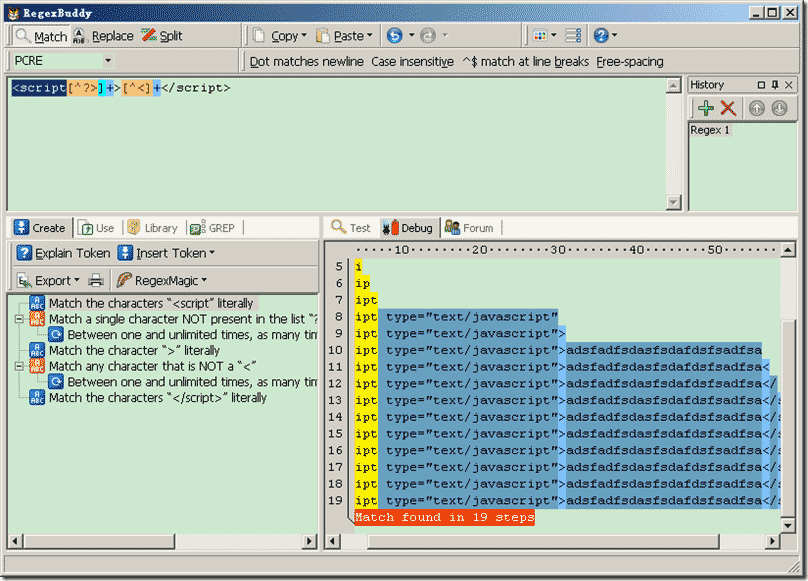
方法(2),我们分析特点发现, 19步,0次回溯! ,步骤只有原先的15%左右,性能几倍的提升了!
从上面我们看到,不同正则表达式,对通用字符配平,性能相差会很大。减少“回溯”是最好的方法,减少回溯其中最主要的方法是:”用最小范围的元字符,尽量避免用过大的元字符1。一般规律如下: 1、使用正确的边界匹配器(^、$、b、B等),限定搜索字符串位置
2、使用具体的元字符、字符类(d、w、s等) ,少用”.”字符
3、使用正确的量词(+、*、?、{n,m}),如果能够限定长度,匹配最佳
4、使用非捕获组、原子组,减少没有必要的字匹配捕获用(?:) 如:我想匹配一些英文字母,它后面接的是数字。如:abc1234,我可以写 “w+d+”,也可以写”[a-zA-Z]+d+” ,其中第一个w+会先匹配所有abc1234,然后回溯,匹配满足d+格式。一共4步,而后面这个只需要2步,步骤减少一半了!好了,今天就先到这里,欢迎大家讨论、交流!