

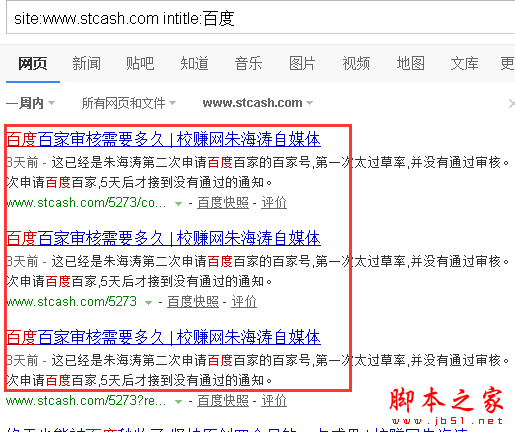
点击进入链接,除了原网页,分别出现:
http://www.stcash.com/5273/comment-page-1
http://www.stcash.com/5273?replytocom=1989
前面一篇文章居然出现一个三级目录,后面一篇文章又类似于动态网页网址。我文章中是没有这两个链接地址的,查看网页源码,看出了一点端倪。
原因分析:
我发现了这两个?replytocom=1989网址的来源:文章评论链接

四个评论刚好对应四个replytocom,百度蜘蛛可能有一定的智能,四个replytocom网址中只收录了一个,但是又不够智能,没有区分出来评论链接和原文链接对应的文章内容是相同的。
comment-page-1网址同样是来源于评论链接,comment-page-1代表着评论页面的第一页。如果我的评论比较多,比如说有1000条评论,那么一页肯定是显示不下去的,就会出现comment-page-2,comment-page-3......这就是评论分页功能,这个功能本质上是防止评论过多时,网页会被拉的很长,导致网页加载速度慢和用户体验差。但是不巧的是,百度蜘蛛依然不能识别出来这和原文
解决方法:
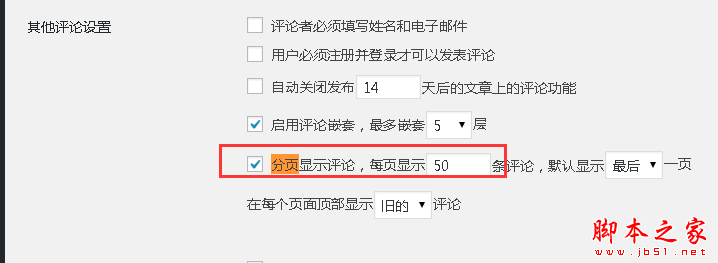
1、对于comment-page-1重复收录,有两种方式解决
1)在wordpress后台关闭评论分页
2)修改robots.txt,加上一句项目的代码
Disallow: /comment-page-
robots.txt在网站根目录,使用 网址/robots.tx就可以看到设置的结果了。如果根目录下没有这个文件
wp-includes/funtion中有这么一段代码:
$output="User-agent:*n"; $public=get_option('blog_public'); if('0'==$public){ $output.="Disallow:/n"; }else{ $site_url=parse_url(site_url()); $path=(!emptyempty($site_url['path']))?$site_url['path']:''; $output.="Disallow:$path/wp-admin/n"; }在 $output.="Disallow:$path/wp-admin/n"; 后面增加一句$output.="Disallow:$path/comment-page-n";
2、对于replytocom重复收录,设置robots.txt文件
Disallow:/*?replytocom=
或者是加上对于包含replytocom的所有链接都加上nofollow链接
add_filter('comment_reply_link','add_nofollow',420,4); functionadd_nofollow($link,$args,$comment,$post){ returnstr_replace("href=","rel='nofollow'href=",$link); }以上就是对文章被百度重复收录的原因及解决方法全部内容的介绍,更多内容请继续关注全福编程网!



