

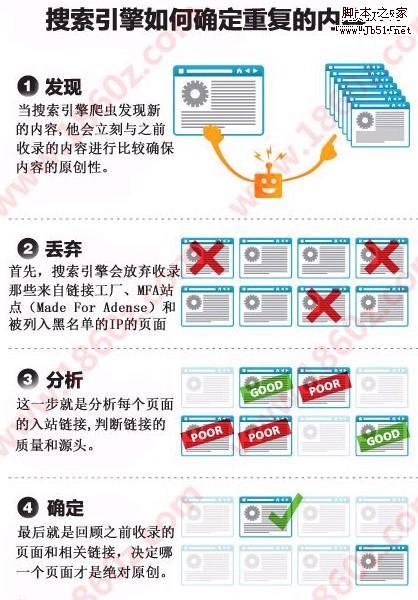
相信大家都能看懂图片的含义吧,比较生动一点,下面简单的给大家表述一下这四个步骤。
1.发现内容:当搜索引擎爬虫发现新内容的时候,他就会理科与之前收录的内容进行比较,确保网站的内容原创性!这一步很关键。如果是伪原创内容的话,请一定保证80%以上的不同!
2.信息丢弃:首先搜索引擎会放弃收录那些来自连接工厂,mfa站点(made for adense)和被列入黑名单的ip页面。
3.链接分析:这一步就是分析每个页面的入站链接,判断链接的质量和源头。这一步也是做导入链接的关键部分,在有限的时间内,做好高质量的链接,保证数量!
4.最后确定:最后就是回顾之前收录的页面和相关链接,决定哪一个页面才是绝对原创。并把原创内容放到排名前面。
总结,这里虽然设计的有的原创,有的伪原创,也有的可能是直接转载。百度蜘蛛和Google机器人默认的排名是最开始的创始地点。最原始的排名越靠前!



