


首先我们要去除它的背景,对于这样稍微复杂的背景,用过去的方法很难做到,上图的例子还不是很明显,我发现很多图片背景色和字母色近似,而且字母颜色是不断变化的,背景也是不断变化的





那我初始的想法是找到图片中使用颜色最多的方法,于是我们用HSL表示各点颜色,接着进行统计,得到最大的几个峰值,这里便是图片中几个最丰富的颜色的L值得累加值
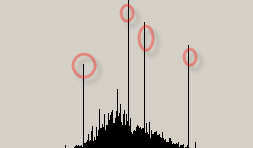
其余的都可以认为是噪音,我们对每个峰值进行分割,得到如下图片

你看这样就把单个颜色图片分割出来了,接下来就是找到图片中除去黑色和白色后的图片

然后进行灰化处理,阀值处理,降噪,得到

接着根据边界检测出来的最左侧x位置,来排序字母顺序

接下来的事情就轻车熟路了,把图片转成标准模板,通过少量学习就达到了95%以上的识别率
c:15 j:8 8:7 t:9 9:4 x:7 4:6 2:4 h:7 f:8 e:18 b:5 y:3 k:4 w:3 g:5 3:5 7:6 r:2 m:3 q:4 v:2 p:3 6:2
以上数据表示 c学习15次 j学习8次…

只要字符不粘连,大部分验证码干扰技术都是可以有办法,所以为什么google验证码看起来很简单,但是没有人能够很好的破解它得原因。
补充,
rise在留言中发现有一些字符加入杂点的问题,由于这种验证码不是很普遍,稍微做了研究

CY3E 这个图片3字中有杂点,其他没有,按照文章中介绍的办法,怎么知道这个3不是像其他颜色杂点一样的图片呢?

我觉得需要加入一个步骤,就是对每次过滤颜色生成出来的图片,进行填充
找到3的杂点原图:

然后我们进行算法填充
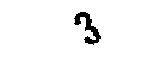
这个图片与其他全部是杂点的图片之间的差别进行过滤,我考虑可以通过以下方法:
1、连贯点的宽度
2、连贯点的个数
这样剩下的就只剩下CY3E的过滤后的图片
至于字符倾斜的问题,我觉得完全可以在机器学习过程中,我们自己旋转正在学习的图片一定角度,例如从-10到+10度,只不过这样的学习库会大一些,但是就10个数字的验证码来说,这点性能损失应该可以忽略不计。



