

DELIMITER $$
set @stmt = 'select userid,username from myuser where userid between ? and ?';
prepare s1 from @stmt;
set @s1 = 2;
set @s2 = 100;
execute s1 using @s1,@s2;
deallocate prepare s1;
$$
DELIMITER ;
用这种形式写的查询,可以随意替换参数,给出代码的人称之为预处理,我想这个应该就是MySQL中的变量绑定吧……但是,在查资料的过程中我却听到了两种声音,一种是,MySQL中有类似Oracle变量绑定的写法,但没有其实际作用,也就是只能方便编写,不能提高效率,这种说法在几个09年的帖子中看到:
http://www.itpub.net/thread-1210292-1-1.html
http://cuda.itpub.net/redirect.php?fid=73&tid=1210572&goto=nextnewset
另一种说法是MySQL中的变量绑定是能确实提高效率的,这个是希望有的,那到底有木有,还是自己去试验下吧。
试验是在本机进行的,数据量比较小,具体数字并不具有实际意义,但是,能用来说明一些问题,数据库版本是mysql-5.1.57-win32免安装版。
本着对数据库不是很熟悉的态度^_^,试验过程中走了不少弯路,此文以结论为主,就不列出实验的设计过程,文笔不好,文章写得有点枯燥,写出来是希望有人来拍砖,因为我得出的结论是:预处理在有没有cache的情况下的执行效率都不及直接执行…… 我对自己的实验结果不愿接受。。如果说预处理只为了规范下Query,使cache命中率提高的话个人觉得大材小用了,希望有比较了解的人能指出事实究竟是什么样子的——NewSilen
实验准备
第一个文件NormalQuery.sql
复制代码 代码如下:
Set profiling=1;
Select * From MyTable where DictID = 100601000004;
Select DictID from MyTable limit 1,100;
Select DictID from MyTable limit 2,100;
/*从limit 1,100 到limit 100,100 此处省略重复代码*/
......
Select DictID from MyTable limit 100,100;
SELECT query_id,seq,STATE,10000*DURATION FROM information_schema.profiling INTO OUTFILE 'd:/NormalResults.csv' FIELDS TERMINATED BY ',' LINES TERMINATED BY 'n';
第二个sql文件 StmtQuery.sql
复制代码 代码如下:
Set profiling=1;
Select * From MyTable where DictID = 100601000004;
set @stmt = 'Select DictID from MyTable limit ?,?';
prepare s1 from @stmt;
set @s = 100;
set @s1 = 101;
set @s2 = 102;
......
set @s100 =200;
execute s1 using @s1,@s;
execute s1 using @s2,@s;
......
execute s1 using @s100,@s;
SELECT query_id,seq,STATE,10000*DURATION FROM information_schema.profiling INTO OUTFILE 'd:/StmtResults.csv' FIELDS TERMINATED BY ',' LINES TERMINATED BY 'n';
做几点小说明:
1. Set profiling=1; 执行此语句之后,可以从information_schema.profiling这张表中读出语句执行的详细信息,其实包含不少内容,包括我需要的时间信息,这是张临时表,每新开一个会话都要重新设置profiling属性才能从这张表中读取数据
2. Select * From MyTable where DictID = 100601000004;
这行代码貌似和我们的实验没什么关系,本来我也是这么认为的,之所以加这句,是我在之前的摸索中发现,执行过程中有个步骤是open table,如果是第一次打开某张表,那时间是相当长的,所以在执行后面的语句前,我先执行了这行代码打开试验用的表
3. MySQL默认在information_schema.profiling表中保存的查询历史是15条,可以修改profiling_history_size属性来进行调整,我希望他大一些让我能一次取出足够的数据,不过最大值只有100,尽管我调整为150,最后能够查到的也只有100条,不过也够了
4. SQL代码我没有全列出来,因为查询语句差不多,上面代码中用省略号表示了,最后的结果是两个csv文件,个人习惯,你也可以把结果存到数据库进行分析
实验步骤
重启数据库,执行文件NormalQuery.sql,执行文件StmtQuery.sql,得到两个结果文件
再重启数据库,执行StmtQuery.sql,执行文件NormalQuery.sql,得到另外两个结果文件
实验结果
详细结果在最后提供了附件下载,有兴趣的朋友可以看下
结果分析
每一个SQL文件中执行了一百个查询语句,没有重复的查询语句,不存在查询cache,统计执行SQL的平均时间得出如下结果
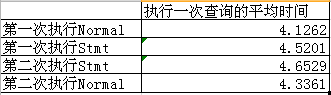
从结果中可以看出,无论是先执行还是后执行,NormalQuery中的语句都比使用预处理语句的要快一些=.=!
那再来看看每一句查询具体的情况,Normal和Stmt的query各执行了两百次,每一步的详细信息如下:
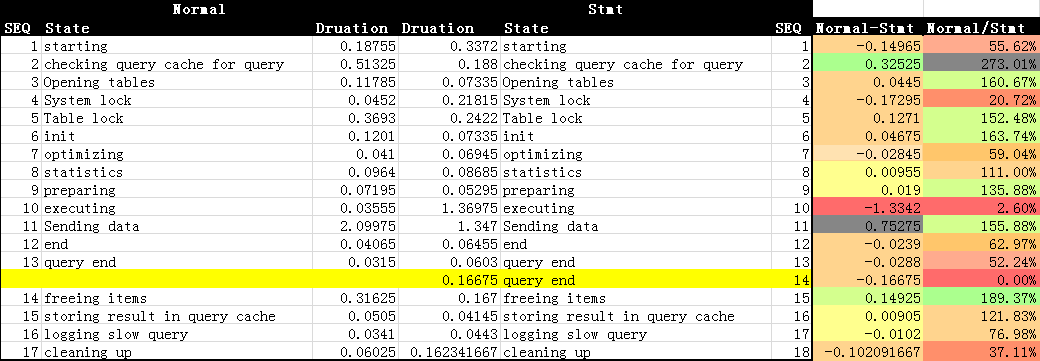
从这里面可以看出,第一个,normalquery比stmtquery少一个步骤,第二个,虽然stmt在不少步骤上是优于normal的,但在executing一步上输掉太多,最后结果上也是落败
最后,再给出一个查询缓存的实验结果,具体步骤就不列了

在查询缓存的时候,Normal完胜……
写在最后
大概情况就是这样,我回忆了一下,网上说预处理可以提高效率的,基本都是用编程的方式去执行查询,不知道这个有没有关系,基础有限,希望园子里的大牛能看到,帮忙解惑
实验结果附件
MySQL预处理实验结果



