

开始
前一阵子,在项目中碰到这样一个SQL查询需求,有两个相同结构的表(table_left & table_right),如下:
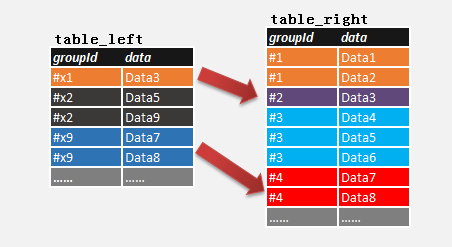
图1.
检查表table_left的各组(groupId),是否在表table_right中存在有一组(groupId)数据(data)与它的数据(data)完全相等.
如图1. 可以看出表table_left和table_right存在两组数据完整相等:

图2.
分析
从上面的两个表,可以知道它们存放的是一组一组的数据;那么,接下来我借助数学集合的列举法和运算进行分析。
先通过集合的列举法描述两个表的各组数据:
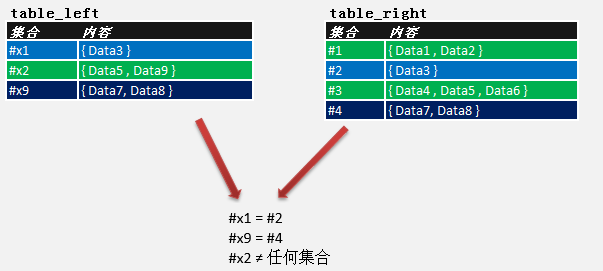
图3.
这里只有两种情况,相等和不相等。对于不相等,可再分为部分相等、包含、和完全不相等。使用集合描述,可使用交集,子集,并集。如下面图4.,我列举出这几种常见的情况:
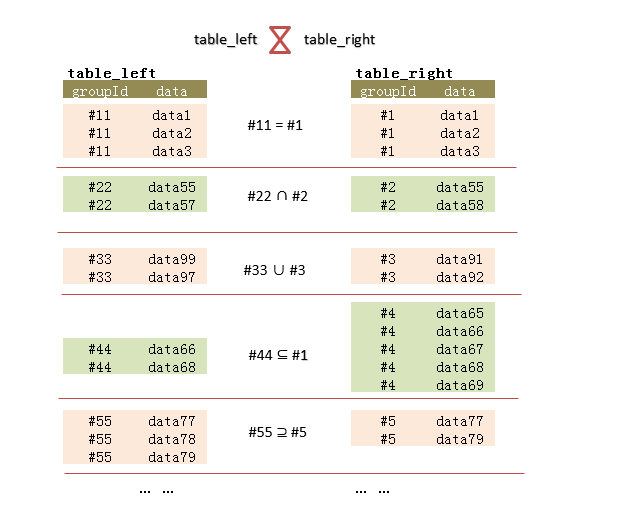
图4.
实现
在数据库中,要找出表table_left和表table_right存在相同数据的组,方法很多,这里我列出两种常用的方法。
(下面的SQL脚本,是以图4.的数据为基础参考)
方法1:
通过"Select … From …Order by … xml for path('') "把各组的data列数据连串起来(如,图4.把table_left的组#11的列data连串起来成"data1-data2-data3"),其他分组(包含表table_right)以此方法实现data列数据连串起来;然后通过比较两表的连串后字段是否存在相等,若是相等就说明这比较多两组数据相等,由此可以判断出表table_left的哪组数据在表table_right存在与它数据完全相等的组。
针对方法1,需要对原表增加一个字段dataPath,用于存储data列数据连串的结果,如:
复制代码 代码如下:alter table table_left add dataPath nvarchar(200)
alter table table_right add dataPath nvarchar(200)
分组连串data列数据并update至刚新增的列dataPath,如:
复制代码 代码如下:update a
set dataPath=b.dataPath
from table_left a
cross apply(select (select '-'+x.data from table_left x where x.groupId=a.groupId order by x.data for xml path('')) as dataPath)b
update a
set dataPath=b.dataPath
from table_right a
cross apply(select (select '-'+x.data from table_right x where x.groupId=a.groupId order by x.data for xml path('')) as dataPath)b
接下来就是查询了,如:
复制代码 代码如下:select distinct a.groupId
from table_left a
where exists(select 1 from table_right x where x.dataPath=a.dataPath)

完整代码:
复制代码 代码如下:View Code
use tempdb
go
if object_id('table_left') is not null drop table table_left
if object_id('table_right') is not null drop table table_right
go
create table table_left(groupId nvarchar(5),data nvarchar(10))
create table table_right(groupId nvarchar(5),data nvarchar(10))
go
alter table table_left add dataPath nvarchar(200)
alter table table_right add dataPath nvarchar(200)
go
create nonclustered index ix_left on table_left(dataPath)
create nonclustered index ix_right on table_right(dataPath)
go
set nocount on
go
insert into table_right(groupId,data)
select '#1','data1' union all
select '#1','data2' union all
select '#1','data3' union all
select '#2','data55' union all
select '#2','data55' union all
select '#3','data91' union all
select '#3','data92' union all
select '#4','data65' union all
select '#4','data66' union all
select '#4','data67' union all
select '#4','data68' union all
select '#4','data69' union all
select '#5','data77' union all
select '#5','data79'
insert into table_left(groupId,data)
select '#11','data1' union all
select '#11','data2' union all
select '#11','data3' union all
select '#22','data55' union all
select '#22','data57' union all
select '#33','data99' union all
select '#33','data99' union all
select '#44','data66' union all
select '#44','data68' union all
select '#55','data77' union all
select '#55','data78' union all
select '#55','data79'
go
update a
set dataPath=b.dataPath
from table_left a
cross apply(select (select '-'+x.data from table_left x where x.groupId=a.groupId order by x.data for xml path('')) as dataPath)b
update a
set dataPath=b.dataPath
from table_right a
cross apply(select (select '-'+x.data from table_right x where x.groupId=a.groupId order by x.data for xml path('')) as dataPath)b
--
select distinct a.groupId
from table_left a
where exists(select 1 from table_right x where x.dataPath=a.dataPath)
方法2:
通过SQL Sever提供的集运算符"Except",判断两组非重复的数据。如果两组针对对方都不存在非重复的数据,就说明这两组数据完全相等。如,表table_left中的组#11和表 table_right中的组#1,对列data进行"Except"集运算,无任是(#11 à #1)进行Except集运算,还是(#1 à #11 )进行Except集合运算,都返回空结果,这就说明组#1 和#11的data数据完全相等,如:
复制代码 代码如下:select data from table_left where groupId='#11' except select data from table_right where groupId='#1'
select data from table_right where groupId='#1' except select data from table_left where groupId='#11'
同样道理,我们把表table_left中的组#11和表 table_right中的组#2,对列data进行"Except"集运算,如:
复制代码 代码如下:select data from table_left where groupId='#11' except select data from table_right where groupId='#2'
select data from table_right where groupId='#2' except select data from table_left where groupId='#11'

只要(#11 à #2 )或 (#2 à #11 )的"Except"集运算结果有记录,就说明两组的数据不相等。
两张表的所有组都进行比较,我们需要通过以下SQL脚本实现,如:
复制代码 代码如下:select distinct a.groupId
from table_left a
inner join table_right b on b.data=a.data
where not exists(select x.data from table_left x where x.groupId=a.groupId except select y.data from table_right y where y.groupId=b.groupId )
and not exists(select x.data from table_right x where x.groupId=b.groupId except select y.data from table_left y where y.groupId=a.groupId )

完整代码:
复制代码 代码如下:View Code
use tempdb
go
if object_id('table_left') is not null drop table table_left
if object_id('table_right') is not null drop table table_right
go
create table table_left(groupId nvarchar(5),data nvarchar(10))
create table table_right(groupId nvarchar(5),data nvarchar(10))
go
create nonclustered index ix_left on table_left(data)
create nonclustered index ix_right on table_right(data)
go
set nocount on
go
insert into table_right(groupId,data)
select '#1','data1' union all
select '#1','data2' union all
select '#1','data3' union all
select '#2','data55' union all
select '#2','data55' union all
select '#3','data91' union all
select '#3','data92' union all
select '#4','data65' union all
select '#4','data66' union all
select '#4','data67' union all
select '#4','data68' union all
select '#4','data69' union all
select '#5','data77' union all
select '#5','data79'
insert into table_left(groupId,data)
select '#11','data1' union all
select '#11','data2' union all
select '#11','data3' union all
select '#22','data55' union all
select '#22','data57' union all
select '#33','data99' union all
select '#33','data99' union all
select '#44','data66' union all
select '#44','data68' union all
select '#55','data77' union all
select '#55','data78' union all
select '#55','data79'
go
--select
select distinct a.groupId
from table_left a
inner join table_right b on b.data=a.data
where not exists(select x.data from table_left x where x.groupId=a.groupId except select y.data from table_right y where y.groupId=b.groupId )
and not exists(select x.data from table_right x where x.groupId=b.groupId except select y.data from table_left y where y.groupId=a.groupId )
方法1 Vs. 方法2 :
方法1和方法2都能找出表table_left在table_right存在数据完全相等的组#11。但性能角度上,方法2比方法1略胜一筹,可以看它们执行过程的统计信息:
方法1:
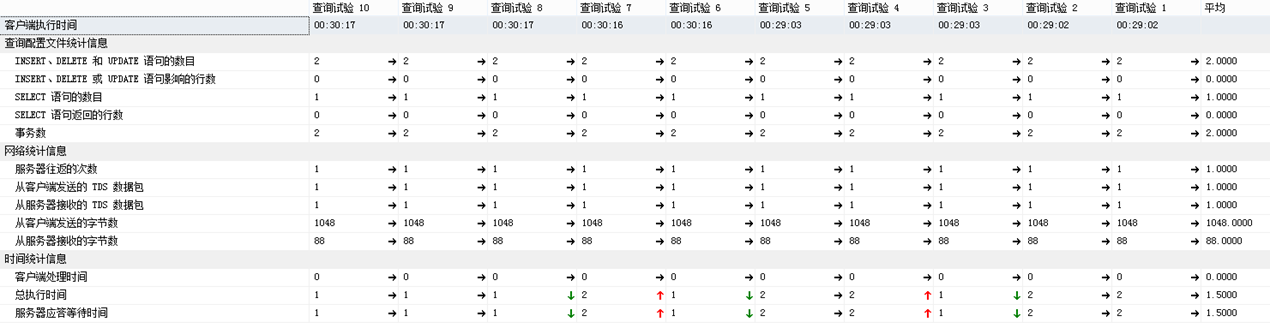
图5.
方法2:
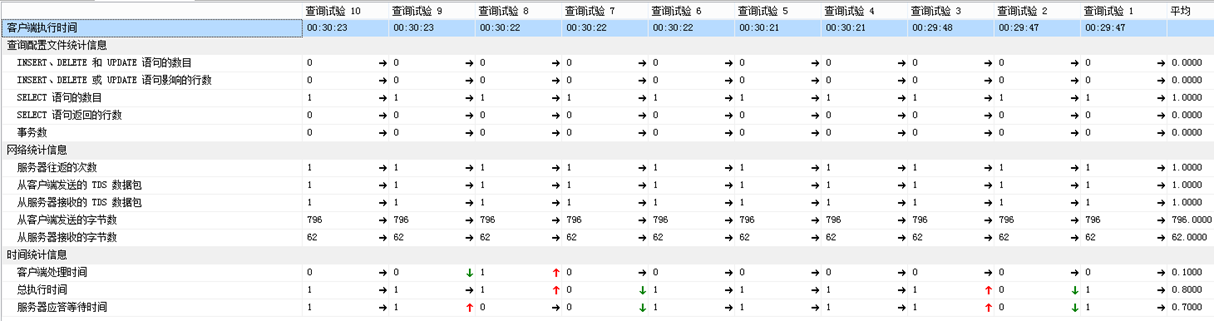
图6.
如果,数据量大情况下,那么方法2比方法1更具有明显的优点。因为方法1,多两个更新dataPath的部分,数据量随着增加,这里位置的更新就耗很多的资源;如果dataPath列数据大小超过900字节,会导致无法在dataPath创建索引,影响后面的Select查询性能。
扩展
这里说扩展,主要是针对上面的方法2来说。在当列data的数据大小超过900字节,或者含有多个数据列要进行比较,看是否存在两组(groupId)的各对应列数据一一相等。
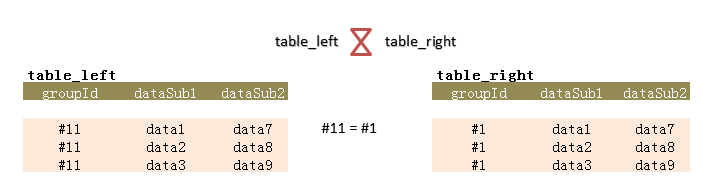
图7.
这样的情况,可对字段dataSub1 & dataSub2 创建一个哈希索引,如:
复制代码 代码如下:alter table table_left add dataChecksum as checksum(dataSub1,dataSub2)
alter table table_right add dataChecksum as checksum(dataSub1,dataSub2)
go
create nonclustered index ix_table_left_cs on table_right(dataChecksum)
create nonclustered index table_right_cs on table_right(dataChecksum)
后面的select查询语句,在Inner Join 部分稍改动下即可,如:
复制代码 代码如下:select distinct a.groupId
from table_left a
inner join table_right b on b.dataChecksum=a.dataChecksum
and b.dataSub1=a.dataSub1
and b.dataSub2=a.dataSub2
where not exists(select x.dataSub1,x.dataSub2 from table_left x where x.groupId=a.groupId except select y.dataSub1,y.dataSub2 from table_right y where y.groupId=b.groupId )
and not exists(select x.dataSub1,x.dataSub2 from table_right x where x.groupId=b.groupId except select y.dataSub1,y.dataSub2 from table_left y where y.groupId=a.groupId )
完整代码:
复制代码 代码如下:View Code
use tempdb
go
if object_id('table_left') is not null drop table table_left
if object_id('table_right') is not null drop table table_right
go
create table table_left(groupId nvarchar(5),dataSub1 nvarchar(10),dataSub2 nvarchar(10))
create table table_right(groupId nvarchar(5),dataSub1 nvarchar(10),dataSub2 nvarchar(10))
go
alter table table_left add dataChecksum as checksum(dataSub1,dataSub2)
alter table table_right add dataChecksum as checksum(dataSub1,dataSub2)
go
create nonclustered index ix_table_left_cs on table_left(dataChecksum)
create nonclustered index table_right_cs on table_right(dataChecksum)
go
set nocount on
go
insert into table_right(groupId,dataSub1,dataSub2)
select '#1','data1','data7' union all
select '#1','data2','data8' union all
select '#1','data3','data9' union all
select '#2','data55','data4' union all
select '#2','data55','data5'
insert into table_left(groupId,dataSub1,dataSub2)
select '#11','data1','data7' union all
select '#11','data2','data8' union all
select '#11','data3','data9' union all
select '#22','data55','data0' union all
select '#22','data57','data2' union all
select '#33','data99','data4' union all
select '#33','data99','data6'
go
--select
select distinct a.groupId
from table_left a
inner join table_right b on b.dataChecksum=a.dataChecksum
and b.dataSub1=a.dataSub1
and b.dataSub2=a.dataSub2
where not exists(select x.dataSub1,x.dataSub2 from table_left x where x.groupId=a.groupId except select y.dataSub1,y.dataSub2 from table_right y where y.groupId=b.groupId )
and not exists(select x.dataSub1,x.dataSub2 from table_right x where x.groupId=b.groupId except select y.dataSub1,y.dataSub2 from table_left y where y.groupId=a.groupId )
小结
对于这个问题,可能还有其他的或更优的解决方法.而且在实际的生产环境中,可能碰到的情况会有所不同,无论如何,需要多分析,多动手多实验,找到最优的解决方法。



