

SQL中经常遇到如下情况,在一张表中有两条记录基本完全一样,某个或某几个字段有些许差别,
这时候可能需要我们踢出这些有差别的数据,即两条或多条记录中只保留一项。
如下:表timeand
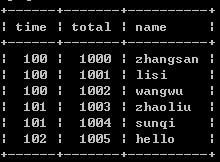
针对time字段相同时有不同total和name的情形,每当遇到相同的则只取其中一条数据,最简单的实现方法有两种
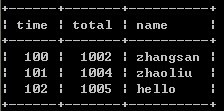
1、select time,max(total) as total,name from timeand group by time;//取记录中total最大的值
或 select time,min(total) as total,name from timeand group by time;//取记录中total最小的值

上述两种方案都有个缺点,就是无法区分name字段的内容,所以一般用于只有两条字段或其他字段内容完全一致的情况
2、select * from timeand as a where not exists(select 1 from timeand where a.time = time and a.total
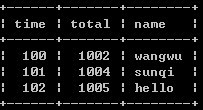
此中方案排除了方案1中name字段不准确的问题,取的是total最大的值
上面的例子中是只有一个字段不相同,假如有两个字段出现相同呢?要求查处第三个字段的最大值该如何做呢?
其实很简单,在原先的基础上稍微做下修改即可:
原先的SQL语句:
select * from timeand as a where not exists(select 1 from timeand where a.time = time and a.total 可修改为: select * from timeand as a where not exists(select 1 from timeand where a.time = time and (a.total 其中outtotal是另外一个字段,为Int类型 以上就是SQL中遇到多条相同内容只取一条的最简单实现方法的全部内容,希望能给大家一个参考,也希望大家多多支持全福编程网。



