

技术方案一:
压缩时间下程序员写出的第一个版本,仅仅为了完成任务,没有从程序上做任何优化,实现方式是利用数据库访问类调用存储过程,利用循环逐条插入。很明显,这种方式效率并不高,于是有了前面的两位同事讨论效率低的问题。
技术方案二:
由于是考虑到大数据量的批量插入,于是我想到了ADO.NET2.0的一个新的特性:SqlBulkCopy。有关这个的性能,很早之前我是亲自做过性能测试的,效率非常高。这也是我向公司同事推荐的技术方案。
技术方案三:
利用SQLServer2008的新特性--表值参数(Table-Valued Parameter)。表值参数是SQLServer2008才有的一个新特性,使用这个新特性,我们可以把一个表类型作为参数传递到函数或存储过程里。不过,它也有一个特点:表值参数在插入数目少于 1000 的行时具有很好的执行性能。
技术方案四:
对于单列字段,可以把要插入的数据进行字符串拼接,最后再在存储过程中拆分成数组,然后逐条插入。查了一下存储过程中参数的字符串的最大长度,然后除以字段的长度,算出一个值,很明显是可以满足要求的,只是这种方式跟第一种方式比起来,似乎没什么提高,因为原理都是一样的。
技术方案五:
考虑异步创建、消息队列等等。这种方案无论从设计上还是开发上,难度都是有的。
技术方案一肯定是要被否掉的了,剩下的就是在技术方案二跟技术方案三之间做一个抉择,鉴于公司目前的情况,技术方案四跟技术方案五就先不考虑了。
接下来,为了让大家对表值参数的创建跟调用有更感性的认识,我将写的更详细些,文章可能也会稍长些,不关注细节的朋友们可以选择跳跃式的阅读方式。
再说一下测试方案吧,测试总共分三组,一组是插入数量小于1000的,另外两组是插入数据量大于1000的(这里我们分别取10000跟1000000),每组测试又分10次,取平均值。怎么做都明白了,Let's go!
1.创建表。
为了简单,表中只有一个字段,如下图所示:

2.创建表值参数类型
我们打开查询分析器,然后在查询分析器中执行下列代码:
Create Type PassportTableType as Table ( PassportKey nvarchar(50)
)
执行成功以后,我们打开企业管理器,按顺序依次展开下列节点--数据库、展开可编程性、类型、用户自定义表类型,就可以看到我们创建好的表值类型了如下图所示:
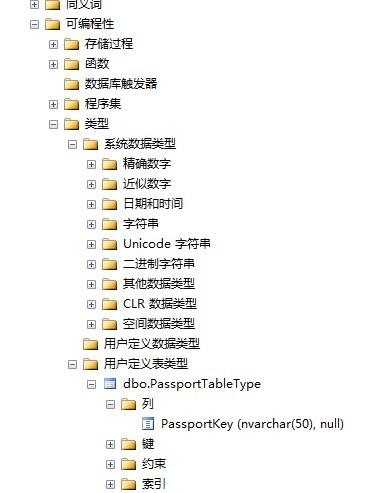
说明我们创建表值类型成功了。
3.编写存储过程
存储过程的代码为:
复制代码 代码如下:
USE [TestInsert]
GO
/****** Object: StoredProcedure [dbo].[CreatePassportWithTVP] Script Date: 03/02/2010 00:14:45 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author:
-- Create date: <2010-3-1>
-- Description:<创建通行证>
-- =============================================
Create PROCEDURE [dbo].[CreatePassportWithTVP]
@TVP PassportTableType readonly
AS
BEGIN
SET NOCOUNT ON;
Insert into Passport(PassportKey) select PassportKey from @TVP
END
可能在查询分析器中,智能提示会提示表值类型有问题,会出现红色下划线(见下图),不用理会,继续运行我们的代码,完成存储过程的创建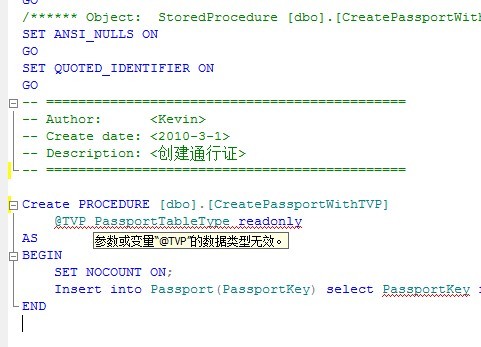
4.编写代码调用存储过程。
三种数据库的插入方式代码如下,由于时间比较紧,代码可能不那么易读,特别代码我加了些注释。
复制代码 代码如下:
using System;
using System.Diagnostics;
using System.Data;
using System.Data.SqlClient;
using com.DataAccess;
namespace ConsoleAppInsertTest
{
class Program
{
static string connectionString = SqlHelper.ConnectionStringLocalTransaction; //数据库连接字符串
static int count = 1000000; //插入的条数
static void Main(string[] args)
{
//long commonInsertRunTime = CommonInsert();
//Console.WriteLine(string.Format("普通方式插入{1}条数据所用的时间是{0}毫秒", commonInsertRunTime, count));
long sqlBulkCopyInsertRunTime = SqlBulkCopyInsert();
Console.WriteLine(string.Format("使用SqlBulkCopy插入{1}条数据所用的时间是{0}毫秒", sqlBulkCopyInsertRunTime, count));
long TVPInsertRunTime = TVPInsert();
Console.WriteLine(string.Format("使用表值方式(TVP)插入{1}条数据所用的时间是{0}毫秒", TVPInsertRunTime, count));
}
///
/// 普通调用存储过程插入数据
///
///
private static long CommonInsert()
{
Stopwatch stopwatch = new Stopwatch();
stopwatch.Start();
string passportKey;
for (int i = 0; i < count; i++)
{
passportKey = Guid.NewGuid().ToString();
SqlParameter[] sqlParameter = { new SqlParameter("@passport", passportKey) };
SqlHelper.ExecuteNonQuery(connectionString, CommandType.StoredProcedure, "CreatePassport", sqlParameter);
}
stopwatch.Stop();
return stopwatch.ElapsedMilliseconds;
}
///
/// 使用SqlBulkCopy方式插入数据
///
///
///
private static long SqlBulkCopyInsert()
{
Stopwatch stopwatch = new Stopwatch();
stopwatch.Start();
DataTable dataTable = GetTableSchema();
string passportKey;
for (int i = 0; i < count; i++)
{
passportKey = Guid.NewGuid().ToString();
DataRow dataRow = dataTable.NewRow();
dataRow[0] = passportKey;
dataTable.Rows.Add(dataRow);
}
SqlBulkCopy sqlBulkCopy = new SqlBulkCopy(connectionString);
sqlBulkCopy.DestinationTableName = "Passport";
sqlBulkCopy.BatchSize = dataTable.Rows.Count;
SqlConnection sqlConnection = new SqlConnection(connectionString);
sqlConnection.Open();
if (dataTable!=null && dataTable.Rows.Count!=0)
{
sqlBulkCopy.WriteToServer(dataTable);
}
sqlBulkCopy.Close();
sqlConnection.Close();
stopwatch.Stop();
return stopwatch.ElapsedMilliseconds;
}
private static long TVPInsert()
{
Stopwatch stopwatch = new Stopwatch();
stopwatch.Start();
DataTable dataTable = GetTableSchema();
string passportKey;
for (int i = 0; i < count; i++)
{
passportKey = Guid.NewGuid().ToString();
DataRow dataRow = dataTable.NewRow();
dataRow[0] = passportKey;
dataTable.Rows.Add(dataRow);
}
SqlParameter[] sqlParameter = { new SqlParameter("@TVP", dataTable) };
SqlHelper.ExecuteNonQuery(connectionString, CommandType.StoredProcedure, "CreatePassportWithTVP", sqlParameter);
stopwatch.Stop();
return stopwatch.ElapsedMilliseconds;
}
private static DataTable GetTableSchema()
{
DataTable dataTable = new DataTable();
dataTable.Columns.AddRange(new DataColumn[] { new DataColumn("PassportKey") });
return dataTable;
}
}
}
比较神秘的代码其实就下面这两行,该代码是将一个dataTable做为参数传给了我们的存储过程。简单吧。
SqlParameter[] sqlParameter = { new SqlParameter("@TVP", dataTable) };
SqlHelper.ExecuteNonQuery(connectionString, CommandType.StoredProcedure, "CreatePassportWithTVP", sqlParameter);5.测试并记录测试结果
第一组测试,插入记录数1000

第二组测试,插入记录数10000

第三组测试,插入记录数1000000

通过以上测试方案,不难发现,技术方案二的优势还是蛮高的。无论是从通用性还是从性能上考虑,都应该是
优先被选择的,还有一点,它的技术复杂度要比技术方案三要简单一些,
设想我们把所有表都创建一遍表值类型,工作量还是有的。因此,我依然坚持我开始时的决定,
向公司推荐使用第二种技术方案。
写到此,本文就算完了,但是对新技术的钻研仍然还在不断继续。要做的东西还是挺多的。
为了方便大家学习和交流,代码文件已经打包并上传了,欢迎共同学习探讨。
代码下载
作者:深山老林
出处:http://wlb.cnblogs.com/



