

大家平时都会使用insert语句,特别是有时候需要一个大批量的数据来做测试,一条一条insert将会是非常慢的,那么我们如何让我们的inser更快呢。
先看个例子:
我们需要在如下这个表中插入测试数据,包含两列,一个是itemid,一个是itemname。如果向这个表中插入103,680,000 条记录,普通的插入方法可能需要20多天才能完成,但是用这里介绍的新方法在5个小时内就能够完成。
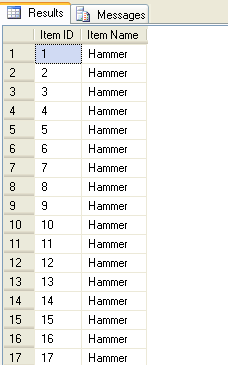
先看一般的数据插入方法,假设我们向上表中插入100000 条数据:
复制代码 代码如下:
CREATE TABLE #tempTable([Item ID] [bigint], [Item Name] nvarchar(30))
DECLARE @counter int
SET @counter = 1
WHILE (@counter < 100000)
BEGIN
INSERT INTO #tempTable VALUES (@counter, 'Hammer')
SET @counter = @counter + 1
END
SELECT * FROM #tempTable
DROP TABLE #tempTable
新的插入方法会使用已经插入的数据来进行下一条记录的操作,原理如下:
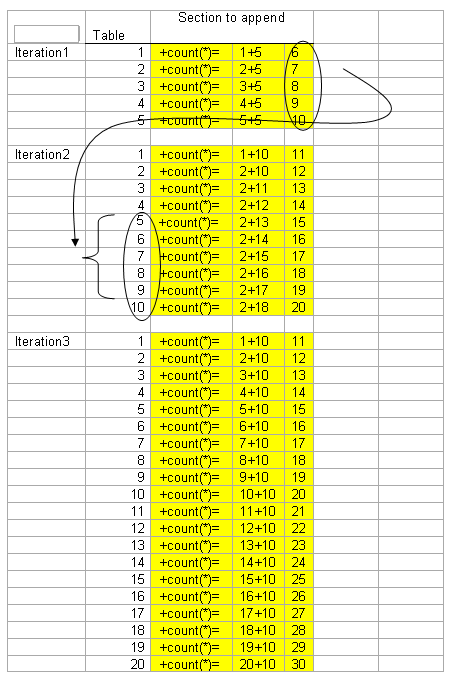
那么看看我的新insert代码:
复制代码 代码如下:
CREATE TABLE #tempTable([Item ID] [bigint], [Item Name] nvarchar(30))
INSERT INTO #tempTable VALUES (1, 'Hammer')
WHILE((SELECT COUNT(*) FROM #tempTable) < 100000)
BEGIN
INSERT INTO #tempTable ([Item ID], [Item Name])
(SELECT [Item ID] + (SELECT COUNT(*) FROM #tempTable), 'Hammer' FROM #tempTable)
END
SELECT * FROM #tempTable
DROP TABLE #tempTable
用第一种方法可能需要几十分钟插入100000数据,但是用第二种只要4秒钟。再改进下,2秒钟就完成:
复制代码 代码如下:
CREATE TABLE #tempTable([Item ID] [bigint], [Item Name] nvarchar(30))
INSERT INTO #tempTable VALUES (1, 'Hammer')
DECLARE @counter int
SET @counter = 1
WHILE(@counter <= 17)
BEGIN
INSERT INTO #tempTable ([Item ID], [Item Name])
(SELECT [Item ID] + (SELECT COUNT(*) FROM #tempTable), 'Hammer' FROM #tempTable)
SET @counter = @counter + 1
END
SELECT * FROM #tempTable
DROP TABLE #tempTable



